 216-447-1551
216-447-1551 info@rbslaw.com
info@rbslaw.com

TROUBLE IN RIVER CITY? “I am Building a Fire, and Every Day I Train, I Add More Fuel”
What was good for Mia Hamm, and probably the rest of us as well, may prove problematic for some of our AI friends. We are indeed adding more fuel. We are adding it at considerable speed. And the nature of that fuel may eventually cause serious problems.
What I think of as data pollution: all those responses your granddaughter is getting when she converses with her imaginary friend on Chat GPT, all the generational stuff that’s appearing on Tik Tok and Meta and a whole lot of other net places, all the conversations with our dead relatives – yes that is really happening at scale, all the answers to questions that Google is providing and now OpenAI as well, because we don’t want to review websites anymore, we just want the answer to our question, preferably right now. None of that is real data. Its data generated by neural networks doing their neural network thing. And there is reason to believe that in the not-too-distant future, that data may present a problem.
Before we explain why, we need to start somewhere near the beginning, not so much in time, but rather conceptually. First, what is AI? What is a neural network? How does AI do what it does? And how do we make it do those things? And just what part of AI am I talking about in these posts? Because there are a lot of different kinds of AI. We’ve been using it for years and it was no big deal. We really didn’t even notice. Now suddenly, it’s electricity.
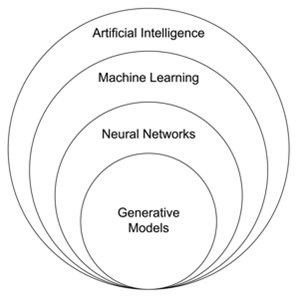
Consider this Venn diagram: The outer circle contains all of artificial intelligence (AI), which basically involves the use of machines to simulate human intelligence via complex algorithms.
1 Image Credit: WikiMedia Commons
Within that outer circle is a second circle containing Machine Learning (ML). ML focuses on developing algorithms and statistical models that condition computers to learn, to forecast, and to make decisions without being explicitly programmed. Typically, ML algorithms are trained on very large datasets to identify patterns or relationships in those datasets.
A significant portion of the dataset is not used for training, but rather to test the model to determine how well the training is working. Once trained, the model then uses those patterns and relationships during inference to make predictions or decisions about different data, i.e., data that was not part of the training dataset.
Operators can train these ML machines in three ways: (1) supervised learning, in which “features” are learned using labeled input data, typically using training data with input-label pairs where the model must learn to process the input to match the labeled pair at the output; (2) unsupervised learning, which involves learning features with unlabeled input data by analyzing the relationship between points in the dataset; and (3) self-supervised learning, in which features are learned using unlabeled data, but the data is augmented, for example, by introducing noise, in such a way that it creates pairs of related data samples.
Irrespective of which approach is used, the key is very large volumes of data. For example, Meta’s Llama 3 model was trained on 15 trillion tokens. More about tokens below. ML’s ability to process very large volumes of data and find subtle patterns, has completely changed the way we analyze big data and produce predictions, forecasts, and the like.
Within the second circle is a third circle containing what is known as Deep Learning (DL). DL, also known as feature learning, is a subset of machine learning that analyzes complex patterns and relationships in data using artificial neural networks that mimic human brain function. These networks are made up of a minimum of three and often many more interconnected layers of neurons. Each layer has at least one and often many more neurons. Each neuron processes data in a hierarchical fashion allowing DL models to learn to a very sophisticated level. DL involves working with large datasets and algorithms that learn and improve their accuracy the more data they process. Training methods include the same three: supervised, unsupervised, and self-supervised.
Within that third circle is a fourth circle containing Generative Artificial Intelligence Models (GenAI). GenAI is driven by Large Language Models (LLMs) that can create new content, such as text, audio and video. The chatbots that started arriving on the net in 2020, are an obvious example of that technology. They can, for example, answer questions, carry on conversations, create video, and find information on the net sought by a user.
LLMs are artificial neural networks that utilize transformer architecture and intensive computation to learn statistical relationships from the large datasets on which they are trained mostly during self-supervised and semi-supervised processes using algorithms to learn patterns and predict what comes next in a word or sentence. In this fashion, they are taught to understand and generate human language, or, in multi-modal architectures, to generate video. Most of the AI hype, noise, commentary, investment, and startups currently in the news is related to the new kid on the block, GenAI. And today we discuss Gen AI.
So, where do these LLMs get the data they train on? While data can originate from a variety of sources, including books, articles, web content, and open-access datasets, as most everyone now knows, those massive datasets are taken from the Internet via a process known as web scraping. Indeed, the vast volumes of data on the net are one of the developments that make LLMs possible. Web scraping is the automated process of extracting data from a website. Web scraping is also known as web harvesting, data extraction, web data extraction, data scraping, and data mining.
Scraping a web page involves fetching it from its location on the net and extracting the data from it. Typically, a web crawler, a form of bot – a computer program that performs automatic repetitive tasks, systematically browses the web. Most information on a web page is "wrapped" in tags that enable the browser to make sense of it, and it's these tags that make it possible for scrapers to work. The web crawler fetches web pages by downloading them much as a browser downloads a page for viewing by a user. Once fetched, the content of a page may be cleaned, searched and reformatted, and its data copied into a spreadsheet or loaded into a database for use in training a neural network.
Modern scraping employs AI to automatically identify relevant page elements of a web page, vary the actions that the page is experiencing, like clicks, scrolls and typing with irregular pauses, using proxies and rotating IP addresses, and solving CAPTCHAS using advanced computer vision algorithms. In other words, AI helps to hide the fact that the web page is being scraped by making it look like it’s just a user viewing the page.
When LLMs are trained, words are broken into “tokens,” which may be a letter, a fragment of a word, a word, or even a phrase. These tokens are then placed in an imaginary “word space” as vectors, defining where in the word space that token can be found. Vectors are placed in the word space where similar words or tokens are located. Because of the complexity of words, language models use vector spaces with hundreds or even thousands of dimensions. For example, GPT-3 uses word vectors with 12,288 dimensions, meaning each vector is represented by 12,288 numbers, defining the word space in which the vector is found for each token.
Training involves feeding the model a series of words. The model then learns to predict the next word in a given sequence. The model then goes through a process whereby it modifies weight assignments for each neuron in the model in an effort to produce the correct next word. This process is repeated millions and even billions of times, depending upon the size of the dataset until optimal performance of the model is achieved.
A model may be fine-tuned by modifying hyperparameters or even modifying the structure of the model to optimize the model’s performance. In ML a hyperparameter is a parameter, such as the learning rate or an optimizer (an algorithm), which specifies details of the learning process. Hyperparameters are classified as model hyperparameters or algorithm hyperparameters. An example of a model hyperparameter is the topology and size of a neural network. An example of an algorithm hyperparameters is the learning rate, which is a tuning parameter in an optimization algorithm that determines the step size at each training iteration while moving toward minimizing the loss function.
On July 24, 2024, researchers from Great Britain and Canada published “AI models collapse when trained on recursively generated data” in Nature. The researchers found that “indiscriminate use of model-generated content in training causes irreversible defects in the resulting models, in which tails of the original content distribution disappear. We refer to this effect as ‘model collapse’ and show that it can occur in LLMs.” They defined model collapse as “a degenerative process whereby, over time, models forget the true underlying data distribution, even in the absence of a shift in the distribution over time.” And they demonstrated that “over time, models start losing information about the true distribution, which first starts with tails disappearing, and learned behaviors converge over the generations to a point estimate with very small variance. Furthermore, we show that this process is inevitable, even for cases with almost ideal conditions for long-term learning.”
“In other words, the use of LLMs at scale to publish content on the Internet will pollute the collection of data to train their successors: data about human interactions with LLMs will be increasingly valuable.”
To be sure, several articles have appeared since the publication of this research paper that take issue with the conclusions. A group of researchers from MIT, Stanford and University of Maryland, among others, published “Is Model Collapse Inevitable? Breaking the Curse of
Recursion by Accumulating Real and Synthetic Data,” wherein they concluded that accumulating successive generations of synthetic data alongside the original real data avoids model collapse. “These results hold across a range of model sizes, architectures, and hyperparameters.” It is unclear, to me at least, whether this paper addresses the issues raised in the Nature paper. It addresses what happens when models are trained on their own generated outputs, and that new data replaces old data over time. The Nature article is not so limited, but rather addresses what happens when the data used is repeatedly taken from the net and “generated by other models.”
In Toward Data Science, Alexander Watson published “Addressing Concerns of Model Collapse from Synthetic Data in AI,” in which he argues that “this extreme scenario of recursive training on purely synthetic data is not representative of real-world development practices.” He argues that “[t]he study’s methodology does not account for the continuous influx of new, diverse data that characterizes real-world AI model training.” He makes it clear, however, that “thoughtful synthetic data generation rather than indiscriminate use” is important. Cutting edge synthetic data is generated by agents iteratively simulating, evaluating, and improving outputs – not simply recursively training on their own output. So, he takes issue with the conclusions in the Nature paper, and then acknowledges that they may be valid.
Other articles have also appeared that explain the phenomenon and reiterate that it is a serious problem. Devin Coldeway explains that models gravitate toward the most common output. They will give you the most popular ordinary response, what I think of as the one with the highest probability in the word space. And since the net is now being overrun by AI-generated content and new AI models are being trained on that content, the models will gravitate toward the common denominator in any given space and will eventually forget any other response.
Coldeway uses dogs as an example and uses the illustration from the original research paper to demonstrate. When asked to generate an image of a dog, the model will produce the most popular one, i.e., the one with the highest probability in the word space. Over time, this will have the effect of producing significantly more pictures of popular dogs than rare ones. Eventually, it will forget that there are any other kinds of dogs, and eventually the model will become useless.
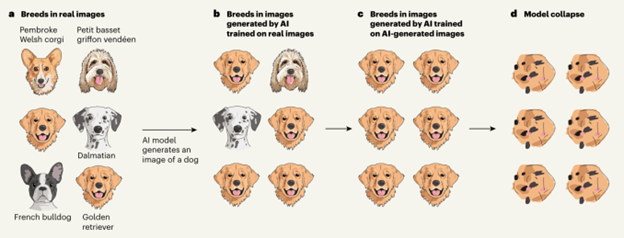
2 Image Credit: Nature
Coldeway continues: “A similar thing happens with language models and others that, essentially, favor the most common data in their training set for answers — which, to be clear, is usually the right thing to do. It’s not really a problem until it meets up with the ocean of chum that is the public web right now.”
On X, Abeba Birhane, a senior fellow in trustworthy AI at the Mozilla Foundation, wrote that model collapse is the “Achilles’ heel that’ll bring the gen AI industry down.” Ed Zitron, who writes a popular Substack on GenAI, wrote, “It’s tough to express how deeply dangerous this is for AI.” Gary Marcus, yet another GenAI critic, wrote on X, “So hard to tell whether AI systems are sucking on each other’s fumes, in a way that could ultimately lead to disaster.”
Dr. Shumailov, one of the authors of the Nature paper, recently said, “I’m sure progress will continue. I don’t know at what scale.” “I don’t think there is an answer to this as of today.” But, in an article in The Globe and Mail on August 14, Joe Castaldo foresees the real problem. Building and training LLMs is horrifically expensive and the ROI is, shall we say, opaque at the moment. “What model collapse could portend, however, is more complexity and cost when it comes to building LLMs.” As Dr. Shumailov says, as a result of these issues, the rate of progress in AI development could slow down, as companies will no longer be able to indiscriminately scrape data from the web. “The advancements that we’ve seen thus far, maybe they’re going to be slowing down a little bit, unless we find another way to discover knowledge.”
To be sure, there are a lot of sceptics in both directions. But the bottom line is that synthetic data, i.e., data produced by GenAI models, may have to be handled with great care if used in training LLMs. Much of today’s practice with respect to the training of LLMs appears to be focused on the scraping of huge amounts of data off the Internet. That practice seems certain to lead to problems.
Remember, we live in interesting times. Be careful out there